一、項(xiàng)目概述
隨著共享單車在城市交通中的普及,產(chǎn)生了海量的騎行數(shù)據(jù),包括用戶信息、騎行軌跡、車輛狀態(tài)、訂單記錄等。這些數(shù)據(jù)具有體量大、增長(zhǎng)快、多樣化的特點(diǎn),傳統(tǒng)的關(guān)系型數(shù)據(jù)庫(kù)難以有效存儲(chǔ)和處理。本項(xiàng)目設(shè)計(jì)并實(shí)現(xiàn)了一個(gè)基于Python的分布式數(shù)據(jù)存儲(chǔ)與處理系統(tǒng),利用Hadoop進(jìn)行海量數(shù)據(jù)存儲(chǔ),通過(guò)Spark進(jìn)行高效數(shù)據(jù)處理,并構(gòu)建可視化大屏進(jìn)行數(shù)據(jù)洞察。
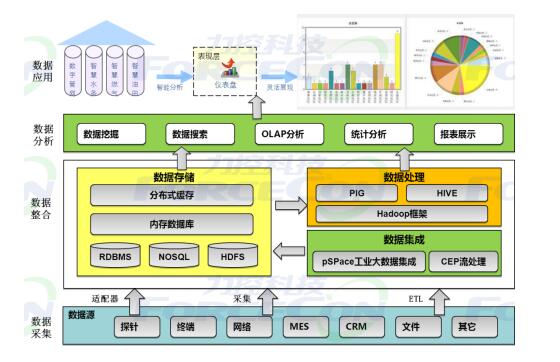
二、系統(tǒng)架構(gòu)設(shè)計(jì)
2.1 技術(shù)棧
- 數(shù)據(jù)存儲(chǔ)層:Hadoop HDFS(分布式文件系統(tǒng))
- 數(shù)據(jù)處理層:Apache Spark(分布式計(jì)算框架)
- 編程語(yǔ)言:Python(PySpark)
- 數(shù)據(jù)采集:Kafka/Flume(實(shí)時(shí)數(shù)據(jù)流)
- 可視化層:ECharts/Dash/Flask
- 協(xié)調(diào)服務(wù):ZooKeeper
- 資源管理:YARN
2.2 架構(gòu)模塊
- 數(shù)據(jù)采集模塊:負(fù)責(zé)從共享單車APP后端API、GPS設(shè)備、物聯(lián)網(wǎng)傳感器等數(shù)據(jù)源采集數(shù)據(jù)
- 數(shù)據(jù)存儲(chǔ)模塊:將原始數(shù)據(jù)、清洗后數(shù)據(jù)、分析結(jié)果存儲(chǔ)到HDFS中
- 數(shù)據(jù)處理模塊:使用Spark進(jìn)行數(shù)據(jù)清洗、轉(zhuǎn)換、分析和建模
- 服務(wù)接口模塊:提供RESTful API供其他系統(tǒng)調(diào)用
- 可視化模塊:構(gòu)建Web大屏展示關(guān)鍵指標(biāo)
三、核心功能實(shí)現(xiàn)
3.1 數(shù)據(jù)存儲(chǔ)設(shè)計(jì)
`python
# HDFS文件目錄結(jié)構(gòu)示例
/sharedbike/
├── rawdata/ # 原始數(shù)據(jù)
│ ├── gpslogs/ # GPS軌跡日志
│ ├── orderrecords/ # 訂單記錄
│ └── bikestatus/ # 車輛狀態(tài)
├── cleaneddata/ # 清洗后數(shù)據(jù)
├── processeddata/ # 處理分析結(jié)果
└── modeldata/ # 模型訓(xùn)練數(shù)據(jù)`
3.2 數(shù)據(jù)處理服務(wù)
主要實(shí)現(xiàn)以下數(shù)據(jù)處理服務(wù):
1. 數(shù)據(jù)清洗服務(wù)`python
from pyspark.sql import SparkSession
from pyspark.sql.functions import col, when
def cleanbikedata(spark, inputpath, outputpath):
# 讀取原始數(shù)據(jù)
df = spark.read.parquet(input_path)
# 數(shù)據(jù)清洗
cleaneddf = df.filter(
(col("latitude").isNotNull()) &
(col("longitude").isNotNull()) &
(col("bikeid").isNotNull())
).withColumn(
"duration_minutes",
when(col("duration") > 0, col("duration") / 60).otherwise(0)
)
# 保存清洗后數(shù)據(jù)
cleaneddf.write.mode("overwrite").parquet(outputpath)
return cleaned_df`
- 數(shù)據(jù)分析服務(wù)
- 熱門騎行區(qū)域分析
- 騎行高峰時(shí)段統(tǒng)計(jì)
- 車輛利用率計(jì)算
- 用戶騎行模式分析
- 異常使用檢測(cè)
3. 數(shù)據(jù)存儲(chǔ)服務(wù)`python
class BikeDataStorage:
def init(self, hdfsurl="hdfs://localhost:9000"):
self.hdfsurl = hdfsurl
def savetohdfs(self, df, path):
"""保存DataFrame到HDFS"""
fullpath = f"{self.hdfsurl}{path}"
df.write.mode("append").parquet(fullpath)
def readfromhdfs(self, path):
"""從HDFS讀取數(shù)據(jù)"""
fullpath = f"{self.hdfsurl}{path}"
return spark.read.parquet(full_path)`
四、可視化大屏實(shí)現(xiàn)
4.1 關(guān)鍵技術(shù)指標(biāo)
- 實(shí)時(shí)監(jiān)控:在線車輛數(shù)、當(dāng)前訂單數(shù)、系統(tǒng)健康狀態(tài)
- 運(yùn)營(yíng)分析:日活用戶、訂單增長(zhǎng)率、車輛周轉(zhuǎn)率
- 時(shí)空分析:熱力圖展示騎行分布、時(shí)段流量統(tǒng)計(jì)
- 預(yù)測(cè)展示:未來(lái)需求預(yù)測(cè)、車輛調(diào)度建議
4.2 大屏界面組件
`python
# 使用Dash構(gòu)建可視化大屏
import dash
import dashcorecomponents as dcc
import dashhtmlcomponents as html
from dash.dependencies import Input, Output
app = dash.Dash(name)
app.layout = html.Div([
html.H1("共享單車運(yùn)營(yíng)監(jiān)控大屏"),
# 第一行:關(guān)鍵指標(biāo)
html.Div([
html.Div([
html.H3("在線車輛"),
html.H2(id="online-bikes")
], className="metric-card"),
# 更多指標(biāo)卡片...
], className="metric-row"),
# 第二行:圖表區(qū)
html.Div([
dcc.Graph(id="heat-map"),
dcc.Graph(id="time-distribution")
], className="chart-row"),
# 定時(shí)刷新
dcc.Interval(id="interval-component", interval=60*1000)
])`
五、系統(tǒng)部署與調(diào)試
5.1 環(huán)境配置
`bash
# 1. Hadoop集群配置
core-site.xml
hdfs-site.xml
yarn-site.xml
2. Spark配置
spark-env.sh
spark-defaults.conf
3. Python環(huán)境
pip install pyspark pandas dash`
5.2 調(diào)試策略
- 單元測(cè)試:對(duì)每個(gè)數(shù)據(jù)處理函數(shù)編寫(xiě)測(cè)試用例
- 集成測(cè)試:測(cè)試HDFS讀寫(xiě)、Spark作業(yè)執(zhí)行
- 性能測(cè)試:大數(shù)據(jù)量下的處理性能測(cè)試
- 日志監(jiān)控:通過(guò)ELK棧收集分析系統(tǒng)日志
5.3 常見(jiàn)問(wèn)題解決
- 內(nèi)存不足:調(diào)整Spark executor內(nèi)存配置
- 數(shù)據(jù)傾斜:使用salting技術(shù)或調(diào)整partition策略
- HDFS連接失敗:檢查網(wǎng)絡(luò)和防火墻設(shè)置
- 作業(yè)失敗:查看YARN日志和Spark UI
六、源碼結(jié)構(gòu)與文檔
6.1 項(xiàng)目結(jié)構(gòu)
shared-bike-data-system/
├── README.md # 項(xiàng)目說(shuō)明
├── requirements.txt # 依賴包列表
├── config/ # 配置文件
├── src/ # 源代碼
│ ├── data_ingestion/ # 數(shù)據(jù)采集
│ ├── data_processing/ # 數(shù)據(jù)處理
│ ├── data_storage/ # 數(shù)據(jù)存儲(chǔ)
│ ├── visualization/ # 可視化
│ └── utils/ # 工具函數(shù)
├── tests/ # 測(cè)試代碼
├── docs/ # 文檔
│ ├── design_doc.md # 設(shè)計(jì)文檔
│ ├── api_doc.md # API文檔
│ └── deployment_guide.md # 部署指南
└── scripts/ # 部署腳本6.2 核心源碼示例
`python
# main.py - 系統(tǒng)主入口
from pyspark.sql import SparkSession
from dataprocessing.cleaner import DataCleaner
from dataprocessing.analyzer import BikeDataAnalyzer
from visualization.dashboard import BikeDashboard
def main():
# 初始化Spark會(huì)話
spark = SparkSession.builder \
.appName("SharedBikeDataSystem") \
.config("spark.executor.memory", "4g") \
.getOrCreate()
# 數(shù)據(jù)清洗
cleaner = DataCleaner(spark)
cleaneddata = cleaner.clean("/sharedbike/raw_data")
# 數(shù)據(jù)分析
analyzer = BikeDataAnalyzer(spark)
analysisresults = analyzer.analyze(cleaneddata)
# 保存結(jié)果
analyzer.saveresults(analysisresults, "/sharedbike/processeddata")
# 啟動(dòng)可視化大屏
dashboard = BikeDashboard(analysis_results)
dashboard.run(host="0.0.0.0", port=8050)
if name == "main":
main()`
七、與展望
本系統(tǒng)成功實(shí)現(xiàn)了基于Hadoop和Spark的共享單車數(shù)據(jù)存儲(chǔ)與處理平臺(tái),具有以下特點(diǎn):
- 高可擴(kuò)展性:分布式架構(gòu)支持?jǐn)?shù)據(jù)量線性增長(zhǎng)
- 高性能處理:Spark內(nèi)存計(jì)算大幅提升處理速度
- 完整解決方案:涵蓋數(shù)據(jù)采集、存儲(chǔ)、處理、可視化全流程
- 易于維護(hù):模塊化設(shè)計(jì),清晰的代碼結(jié)構(gòu)
未來(lái)優(yōu)化方向:
- 引入實(shí)時(shí)流處理,實(shí)現(xiàn)秒級(jí)數(shù)據(jù)更新
- 集成機(jī)器學(xué)習(xí)模型,實(shí)現(xiàn)智能調(diào)度預(yù)測(cè)
- 增加多數(shù)據(jù)源支持,整合天氣、交通等外部數(shù)據(jù)
- 優(yōu)化可視化大屏,增加交互式分析功能
通過(guò)本系統(tǒng)的實(shí)施,共享單車運(yùn)營(yíng)商可以更好地理解用戶行為、優(yōu)化車輛調(diào)度、提升運(yùn)營(yíng)效率,為智慧城市建設(shè)提供數(shù)據(jù)支撐。