在云原生和微服務架構日益普及的今天,傳統的日志系統(如 ELK Stack)雖然功能強大,但其資源消耗高、部署復雜和成本高昂的問題也逐漸顯現。Grafana Loki 應運而生,作為一款受 Prometheus 啟發的輕量級日志聚合系統,它旨在以極低的資源開銷實現高效的日志收集、索引和查詢。本文將通過圖解的方式,深入剖析 Loki 的工作架構、數據處理流程以及其創新的存儲服務設計。
一、核心設計理念:不為日志內容索引,只為日志標簽索引
Loki 最核心的設計理念與 Prometheus 一脈相承:只對日志的元數據(即標簽)建立索引,而不對日志內容本身進行全文索引。日志內容本身以壓縮塊的形式原樣存儲。這種設計帶來了革命性的優勢:
- 成本極低:索引體積大幅縮小(通常只有日志數據體積的1%到2%),存儲和查詢成本顯著下降。
- 運維簡單:架構簡潔,組件少,與 Prometheus、Grafana 生態無縫集成。
- 高效查詢:通過標簽快速縮小搜索范圍,然后在范圍內的日志流中進行全文搜索(Grep),非常適合基于時間范圍和標簽的查詢模式。
二、Loki 工作架構圖解
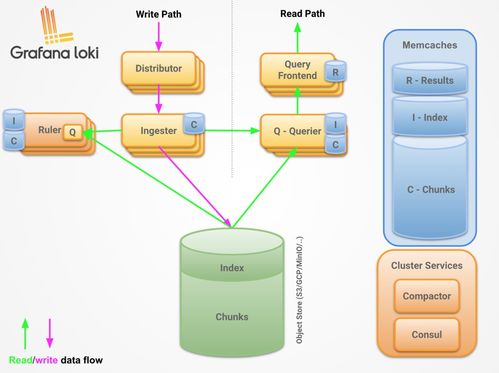
一個典型的 Loki 集群主要由三個核心組件構成,其協作關系如下圖所示:
[日志生產者] (K8s Pods, 節點等)
│
▼ (通過 Promtail/Docker Driver/Fluent-bit 等推送)
[Distributor] (分發器) ─── 寫入 ───> [Ingester] (攝取器) ─── 寫入 ───> [存儲]
│ │
└────────────────── 查詢 ──────────────────────────────┘
│
▼
[Querier] (查詢器) <─── [Grafana/LogCLI 用戶查詢]
│
└─── 讀取索引 ───> [索引存儲]1. Distributor(分發器)
- 職責:接收來自客戶端(如 Promtail)的日志流推送請求(HTTP/HTTPS)。
- 關鍵處理:
- 驗證:檢查日志格式和標簽的有效性。
- 分片:根據日志的標簽集(Label Set)和哈希算法,將日志流路由到對應的 Ingester 節點,確保同一日志流的數據發送到同一個 Ingester,保證順序性。
- 復制:根據配置的復制因子(Replication Factor),將數據復制到多個 Ingester 以實現高可用。
2. Ingester(攝取器)
- 職責:接收來自 Distributor 的日志流,在內存中構建數據塊(Chunks),并定期將這些塊持久化到后端存儲。
- 關鍵處理:
- 內存緩存:日志首先被寫入內存中的“尾塊”(Tail Block),并響應最新日志的查詢。
- 塊切割:基于配置的時間間隔(如1小時)或塊大小,將內存中的日志數據壓縮并切割成不可變的“塊”。
- 寫入存儲:將完整的塊及其關聯的索引條目(標簽 -> 塊引用)分別寫入 對象存儲 和 索引存儲。
- 寫入確認:只有在塊被成功持久化后,Ingester 才會向 Distributor 返回成功的寫入確認。
3. Querier(查詢器)
- 職責:處理來自 Grafana 或 LogCLI 的日志查詢請求。
- 關鍵處理:
- 解析查詢:解析 LogQL 查詢語句,提取時間范圍和標簽匹配器。
- 查詢索引:向索引存儲查詢,找出在指定時間范圍內、匹配標簽的所有日志塊(Chunks)的引用。
- 獲取數據:根據塊引用列表,從對象存儲中并行加載這些壓縮的日志塊。
- 執行查詢:在加載的日志數據中執行過濾(如
|= "error")和聚合操作。
- 合并結果:將從 Ingester(熱數據)和存儲(冷數據)獲取的結果合并、排序后返回給用戶。
三、數據處理流程詳解
寫入路徑(Write Path):
1. 日志采集:客戶端(如 Promtail)從文件、系統日志或容器標準輸出采集日志,并附加一組標簽(如 job="nginx", pod="nginx-abc")。
2. 推送與分發:客戶端將日志流推送給 Distributor。Distributor 通過一致性哈希,找到目標 Ingester。
3. 內存處理:Ingester 將日志追加到對應日志流的內存塊中。
4. 持久化:滿足條件后,Ingester 將內存塊壓縮(通常使用 gzip、snappy 或 lz4),生成一個塊文件,然后:
- 將該塊文件上傳至對象存儲(如 S3、GCS、MinIO)。
- 將該塊的元數據(標簽、時間戳、塊存儲路徑)寫入索引存儲(如 DynamoDB、Cassandra、BoltDB)。
查詢路徑(Query Path):
1. 接收查詢:Querier 收到一個 LogQL 查詢,例如 {job="api-server"} |= "timeout"。
2. 索引查找:Querier 查詢索引存儲,獲取所有標簽包含 job="api-server" 且在查詢時間范圍內的塊引用列表。
3. 數據加載:Querier 同時執行兩項操作:
- 從對象存儲加載所有相關塊。
- 向所有 Ingester 查詢,獲取尚未被持久化的“熱數據”。
- 本地執行:Querier 在本地解壓并遍歷所有日志行,應用過濾條件(
|= "timeout")。 - 返回結果:將過濾后的日志行按時間排序,返回給前端。
四、存儲服務:解耦的索引與數據存儲
Loki 存儲設計的精妙之處在于將索引和塊數據分離,這為靈活性和成本優化提供了巨大空間。
- 索引存儲(Index Storage):
- 存儲內容:僅存儲“標簽 -> 塊引用”的映射關系。這是一個鍵值查詢,要求較高的隨機讀寫性能。
- 可選后端:
- 單機模式:使用本地文件(如 BoltDB),簡單易用。
- 微服務/集群模式:使用 NoSQL 數據庫,如 AWS 的 DynamoDB、Google 的 Bigtable,或開源的 Cassandra。這些數據庫擅長處理高并發的鍵值查詢,且易于擴展。
- 塊數據存儲(Chunk Storage / Object Storage):
- 存儲內容:存儲壓縮后的、不可變的日志數據塊。這是一個順序追加寫、批量讀取的場景。
- 首選后端:對象存儲,如 Amazon S3、Google Cloud Storage (GCS)、Azure Blob Storage 或兼容 S3 的私有存儲(如 MinIO、Ceph)。
- 優勢:對象存儲成本極低、無限擴展、持久性高,完美契合 Loki 存儲大容量、低頻訪問日志數據的需求。
存儲架構圖解:`
[Loki 集群]
/ \
/ \
(索引查詢/寫入) (數據塊上傳/下載)
/ \
▼ ▼
[索引存儲] [對象存儲]
(DynamoDB/Cassandra) (S3/GCS/MinIO)`
五、與優勢
通過以上圖解與分析,我們可以看到 Grafana Loki 架構的清晰與高效:
- 面向云原生:天然支持 Kubernetes,標簽模型與 Prometheus 指標完美對應。
- 成本效益:分離索引與數據,利用廉價對象存儲,總擁有成本(TCO)遠低于傳統方案。
- 查詢高效:通過標簽索引快速定位,避免了不必要的大規模全文檢索。
- 運維簡化:組件職責單一,與 Grafana 深度集成,提供開箱即用的可視化體驗。
Loki 并非要替代所有日志系統,它在處理 調試、故障排查、審計 以及需要將日志與指標、鏈路追蹤關聯的 可觀測性 場景中表現出色。對于需要復雜日志分析、長期趨勢報告的場景,可能仍需結合其他工具。但其創新的架構無疑為日志管理領域帶來了一個極具吸引力的輕量級選擇。