在數據驅動的時代,大數據工程師已成為技術領域的明星崗位。但這條成長之路并非坦途,需要扎實的底層功底與靈活的應用能力相結合。本文將從數據處理與存儲服務這一核心切入,為你梳理一條從理論到實踐、從底層到應用的清晰成長路徑,并附上關鍵的學習路線圖。
一、 堅實的地基:底層核心技能
- 計算機科學基礎:這是所有技術的根基。必須熟練掌握數據結構(如B樹、哈希表、圖)、算法(排序、搜索、動態規劃)、操作系統(進程/線程管理、內存管理、I/O)和計算機網絡(TCP/IP協議棧、HTTP/HTTPS)。理解這些原理,才能更好地駕馭上層的大數據工具。
- Linux與Shell編程:大數據生態幾乎都構建在Linux之上。熟練使用Linux命令、進行環境配置、性能監控,并能編寫Shell腳本進行自動化運維,是日常工作的基本要求。
- 編程語言:
- Java/Scala:Hadoop生態(HDFS, MapReduce, YARN, HBase)及其多數組件由Java編寫,Scala則是Spark的首選語言。深入理解JVM、多線程、網絡編程至關重要。
- Python:在數據清洗、分析、機器學習及腳本編寫方面不可或缺。需熟悉Pandas、NumPy等庫。
二、 核心支柱:大數據處理與存儲框架
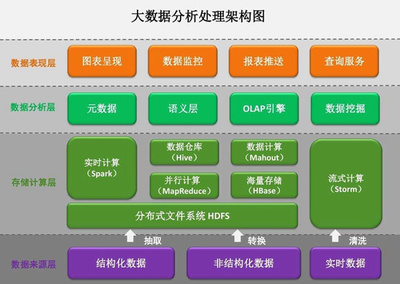
- 分布式存儲基石 - HDFS:深入理解其架構(NameNode, DataNode)、容錯機制、讀寫流程與高可用配置。它是海量數據存儲的起點。
- 批處理引擎:
- Hadoop MapReduce:理解其“分而治之”的編程模型(Map, Shuffle, Reduce階段)是入門經典,有助于理解分布式計算的核心思想。
- Apache Spark:當前批處理與流處理的事實標準。必須精通其核心概念(RDD/DataFrame/Dataset)、執行引擎(DAG調度、內存計算)、性能調優及Spark SQL。
- 流處理引擎:
- Apache Flink:以其高吞吐、低延遲和精確一次(Exactly-Once)語義著稱,是現代流處理的首選。需掌握其時間窗口、狀態管理、CEP等概念。
- Apache Kafka Streams / Spark Streaming:根據技術棧選型,至少精通其一。
- 數據存儲與查詢:
- NoSQL數據庫:根據場景選擇。HBase(列式存儲,適用于隨機讀寫),Cassandra(去中心化,高可用寫),MongoDB(文檔型,靈活模式)。
- 數據倉庫:Hive(基于HDFS的SQL引擎,理解其元數據管理與執行引擎),以及云原生或MPP架構的倉庫如Apache Doris, ClickHouse, Snowflake等,用于OLAP分析。
- 資源管理與協調:
- YARN:Hadoop生態的資源調度器,理解其組件(ResourceManager, NodeManager)與調度策略。
- Apache ZooKeeper / etcd:分布式協調服務,用于配置管理、命名服務、分布式鎖,是許多高可用系統的基石。
三、 上層建筑:數據集成、治理與云服務
- 數據集成與同步:掌握Sqoop(關系型數據庫與HDFS/Hive間傳輸)、Flume(日志采集)、DataX、Canal(增量數據同步)等工具。
- 工作流調度:使用Apache Airflow或DolphinScheduler等工具編排復雜的數據處理任務流,實現自動化。
- 數據治理與質量:了解元數據管理(如Apache Atlas)、數據血緣、數據質量監控體系,確保數據的可信與可用。
- 云原生大數據服務:擁抱云時代。熟悉阿里云MaxCompute/DataWorks、AWS EMR/Redshift/S3、Azure HDInsight/Data Lake等主流云平臺的服務,理解其與開源組件的對應關系與優勢。
四、 進階應用:走向數據價值
- 數據湖與湖倉一體:理解數據湖(如Delta Lake, Apache Iceberg, Hudi)的概念,實現數據統一存儲與ACID事務,構建湖倉一體架構。
- 實時數倉與數據應用:能夠基于Flink/Spark Streaming + Kafka + OLAP數據庫(如ClickHouse)構建實時數倉,支撐實時大屏、即席查詢等業務。
- 性能調優與故障排查:這是區分普通與資深工程師的關鍵。需具備集群性能監控(如Prometheus + Grafana)、JVM調優、Shuffle優化、數據傾斜處理、全鏈路問題診斷的能力。
五、 大數據工程師學習路線圖(建議順序)
`
第一階段:筑基 (1-3個月)
計算機基礎 -> Linux/Shell -> Java核心 -> SQL深入
第二階段:核心框架入門 (3-6個月)
Hadoop (HDFS, YARN, MapReduce) -> Hive -> Zookeeper -> Spark Core & SQL -> Kafka
第三階段:縱深與擴展 (4-8個月)
- 存儲層:HBase / 一種云數據倉庫
- 計算層:Flink (或深入Spark Streaming)
- 調度與集成:Airflow, Sqoop/DataX
- 容器化:Docker, Kubernetes基礎
第四階段:體系化與實戰 (持續進行)
- 項目實戰:搭建離線/實時數倉項目
- 性能調優:深入JVM、Spark/Flink參數、集群監控
- 架構進階:學習數據湖、湖倉一體、Lambda/Kappa架構
* 云平臺:至少掌握一家主流云的大數據服務套件`
老司機寄語:大數據領域技術迭代迅速,但底層原理和核心思想相對穩定。切忌盲目追逐新工具,而應深入理解分布式系統的核心——如何分而治之、如何保證數據一致性與可用性、如何實現可擴展性。理論學習與動手實踐必須雙線并行,通過搭建環境、閱讀源碼、參與項目來不斷鞏固和深化。保持好奇心與持續學習的能力,是在這條路上行穩致遠的不二法門。